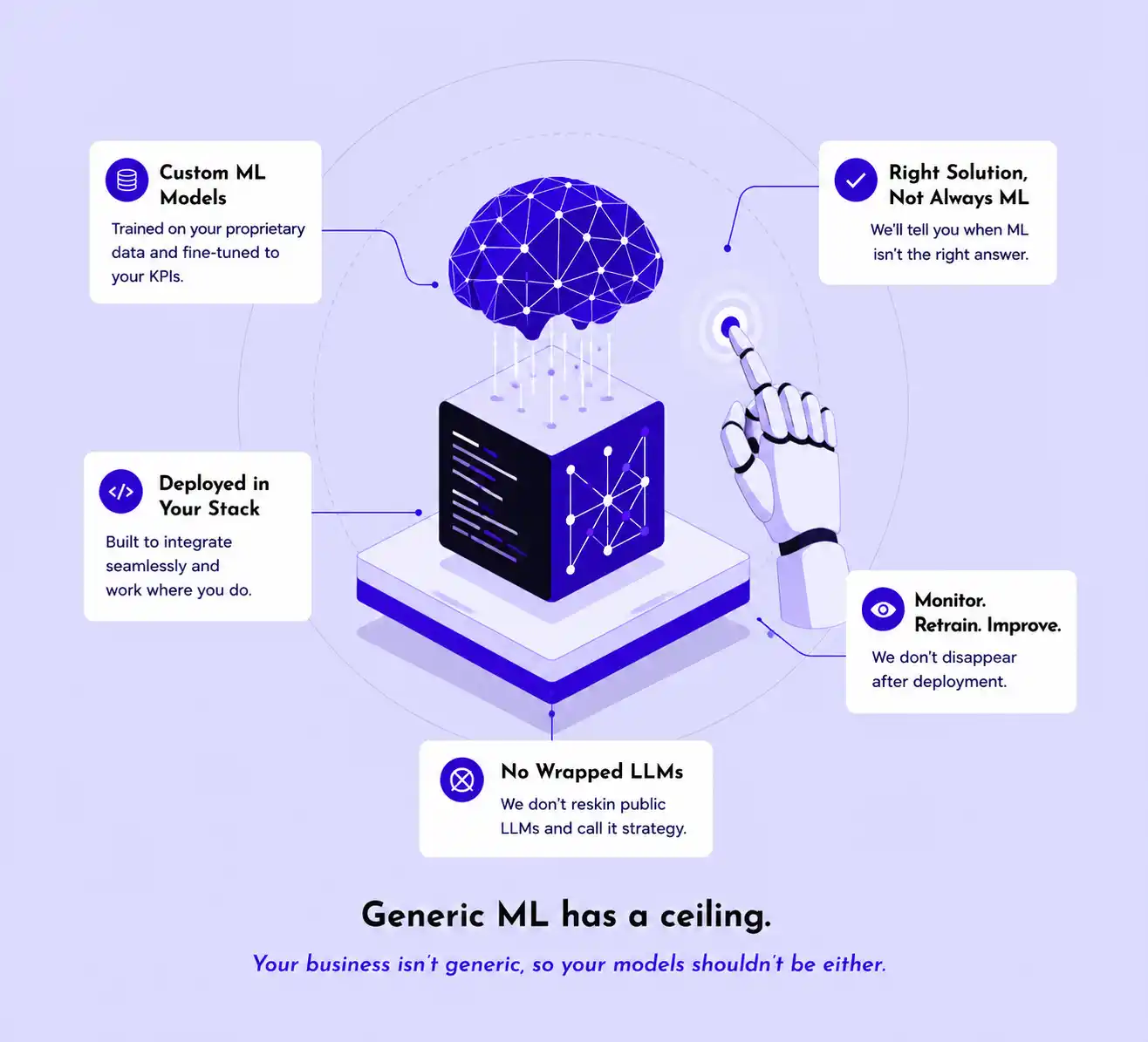
Generic ML Has a Ceiling
Your business isn’t generic, so your models shouldn’t be either.
Pre-trained APIs are great for demos. They struggle the moment your data, your edge cases, or your domain language enters the room. Custom machine learning solutions close that gap by learning from your reality, not a public dataset assembled by someone who’s never met your customers.
Here’s what we actually do (and don’t do):
- We do: Build ML models trained on your proprietary data, fine-tuned to your KPIs, and deployed inside your stack.
- We do: Tell you when ML isn’t the right answer. Sometimes a rules engine wins. We’ll say so.
- We don’t: Wrap a public LLM in a logo and call it a custom AI strategy.
We don’t: Disappear after deployment. Models drift. We monitor and retrain.
End-to-End Generative AI Development Services
Each service maps to a real problem we have shipped a fix for.
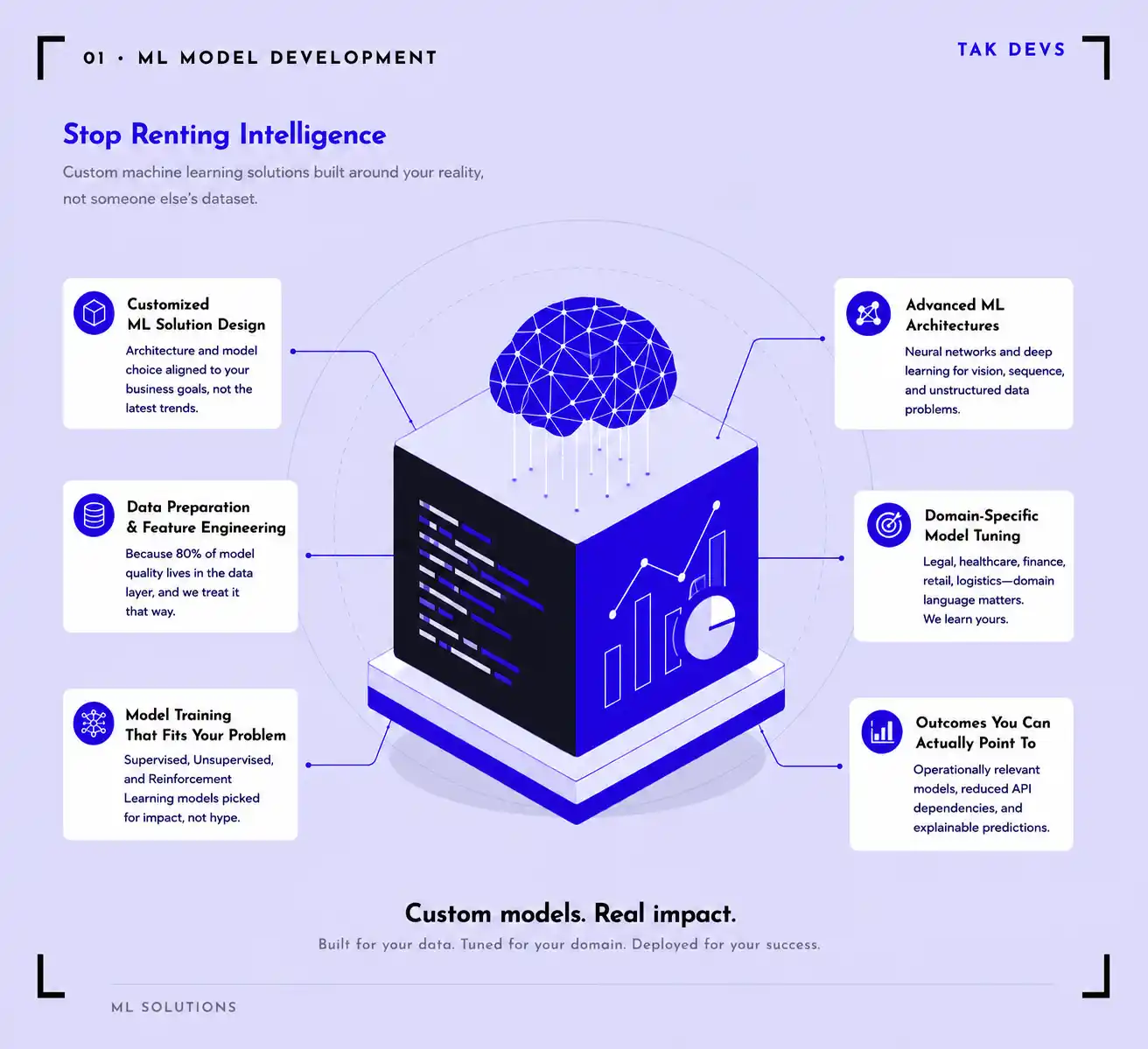
ML Model Development
Stop Renting Intelligence
What we build:
- Customized ML Solution Design — architecture and model choice aligned to your business goals, not the latest Hacker News headline.
- Data Preparation and Feature Engineering — because 80% of model quality lives in the data layer, and we treat it that way.
- Supervised, Unsupervised, and Reinforcement Learning Models — picked based on your problem, not the algorithm we happen to like this quarter.
- Neural Networks and Deep Learning Architectures — for vision, sequence, and unstructured data problems where classical ML hits a wall.
- Domain-Specific Model Tuning — legal, healthcare, finance, retail, logistics. Domain language matters. We learn yours.
Outcomes you can actually point to:
- Models that reflect your operational reality, not a Kaggle competition.
- Reduced dependency on third-party APIs that change pricing without warning.
- Predictions explainable enough to defend in a compliance review.
Model Training & Fine-Tuning
A model untrained on your data is just expensive guessing.
What’s included:
- Optimized Model Training — iterative training loops with validation, early stopping, and honest reporting on what isn’t working yet.
- Hyperparameter Tuning — Bayesian optimization, grid and random search, all in service of one number: business performance.
- Transfer Learning and Fine-Tuning — start from a pre-trained foundation, then teach it your domain so you don’t pay to relearn the alphabet.
- Continuous Learning Pipelines — models that update on new data instead of going stale six weeks after launch.
- Bias Detection and Mitigation — because a model that’s accurate on average and wrong about your most important customer segment is not actually accurate.
What changes after we’re done:
- 40% improvement in prediction reliability for business decisions, on average across our engagements.
- 50% better alignment between model output and the KPI your CFO actually tracks.
- Documentation a future engineer can read without calling you.


Algorithm Selection & Customization
XGBoost isn’t always the answer, no matter what LinkedIn says.
Picking an algorithm is less about hype and more about your data shape, latency requirements, and how much you’ll need to explain the decision later. Algorithm selection and customization is where seasoned teams quietly out-deliver fashionable ones.
What we evaluate:
- Algorithm Evaluation and Selection — benchmarking classical ML, ensemble methods, and deep learning against your specific data signature.
- Custom Algorithm Development — when nothing off-the-shelf fits, we build proprietary algorithms tailored to your edge cases.
- Ensemble and Hybrid Approaches — combining models to squeeze out the last few accuracy points that actually move revenue.
- Explainability Layers — SHAP, LIME, and counterfactual explanations so your model decisions survive audit and customer support.
- Latency and Cost Optimization — a 99.2% accurate model that takes 4 seconds to respond is a 0% accurate model in production.
Numbers we typically deliver:
- 25% simpler decision-making processes through automation of routine classification.
- 30% improvement in solving the gnarly business problems your team has parked for years.
ML Model Deployment
Production deployment is where most ML projects go to die.
The path from “it works on my laptop” to “it works for 80,000 users” is where most ML projects quietly stall. ML model deployment is half engineering, half plumbing, and entirely necessary.
How we deploy:
- Cloud-Based Model Deployment — on AWS, Azure, or GCP, with scalable infrastructure that costs what it should, not what it could.
- Containerization and Orchestration — Docker, Kubernetes, and serverless options based on actual traffic patterns.
- API and Microservices Integration — so your existing applications can call the model without anyone rewriting half the codebase.
- Edge ML Deployment — for use cases where latency, privacy, or offline operation demand the model run on-device.
- Scalability and Performance Optimization — load testing, autoscaling, and graceful degradation when traffic spikes.
Operational wins:
- Reduced infrastructure costs and faster time-to-market for ML applications.
- Risk mitigation for fluctuating workloads through smart autoscaling.
- Reliable performance under varying real-world conditions.


MLOps & Continuous Optimization
Deploy day is mile one. We stay for the whole marathon.
A model deployed in January isn’t the same model in June. Customer behaviour shifts, suppliers change, the world updates itself without sending you a memo. MLOps and continuous optimization keeps your investment from quietly degrading into a liability.
What ongoing operations look like:
- Model Monitoring — accuracy, latency, data drift, concept drift, and prediction distribution, all on one dashboard.
- Automated Retraining Pipelines — so models stay current as new data arrives, without a person babysitting cron jobs.
- A/B Testing and Champion-Challenger Frameworks — compare model versions on live traffic before fully promoting them.
- Incident Response and Rollback — if something breaks, we know within minutes, not next quarter’s QBR.
Performance Reporting — monthly reviews tied to your business metrics, in plain English, not training-loss graphs.
Computer Vision & NLP Solutions
Most of your data is images and text, not spreadsheets.
If your business runs on documents, photos, contracts, calls, or shelf inventory, classical ML on rows and columns leaves most of your value on the table. Computer vision and natural language processing extend custom ML into the messy, unstructured 80% of enterprise data.
Vision capabilities:
- Object Detection and Image Classification for quality control, retail, and security.
- OCR and Document Understanding for paperwork-heavy workflows that nobody enjoys.
- Video Analytics for behaviour, safety, and engagement insights.
- Visual Search and Similarity Matching for e-commerce and inventory use cases.
Language capabilities:
- Text Classification and Entity Extraction for support tickets, contracts, and emails.
- Sentiment and Intent Analysis for voice of customer and product feedback.
- Domain-Tuned Language Models trained on your terminology, not the public internet’s.
- Retrieval-Augmented Generation (RAG) for grounded, citation-backed responses on your knowledge base.

Trusted and recognized across the industry





How TAK Devs Works
Process diagrams look the same at every agency. What matters is what actually happens inside each phase. Here is how we work in practice:
Discovery Call
A focused conversation to understand your goals, challenges, and vision. We ask the right questions to uncover what you truly need — before a single line of code is written.
Scoping Workshop
We translate your goals into a clear, actionable plan. Features are prioritised, timelines are set, and everyone aligns on what success looks like eliminating guesswork from day one.
Sprint Delivery
We build in short, focused cycles, shipping real, working software every sprint. You see progress continuously, give feedback early, and stay in control of where the product is heading.
Launch & Handoff
Your product goes live with confidence. We handle deployment, documentation, and knowledge transfer, ensuring your team is fully equipped to own and operate what we built together.
Ongoing Support
Our relationship doesn't end at launch. We monitor, maintain, and improve your product over time, fixing issues fast and helping you evolve as your users and business grow.
Struggling to keep up with development demands?
See how we can streamline your workflow.
No commitment required | Takes 20 minutes !

Three Rooms We Keep
Getting Called Into
We're not a fit for everyone. We're a very good fit for these three people — and they usually find us at the same moment in their year.
Burning runway on pilots that never ship
- You raised on an AI thesis and need a defensible model, not a wrapper.
- Your previous vendor delivered a Jupyter notebook and an invoice.
- You want a small, fast team that ships and tells the truth on Friday standups.
Watching a modernisation programme quietly stall
- Your platform team is great at infrastructure, less practised at the ML lifecycle.
- You need a specialist partner who plugs into your stack without political drama.
- You'd rather pay for outcomes than for a Gantt chart.
Paying three headcount for one good pipeline
- Manual reconciliation, classification, or routing is eating margin.
- Off-the-shelf SaaS solves 70% of the problem and ignores your 30%.
- You need ML that fits how your team actually works, not the other way around.
Where Our ML Lives
In Production
Domain context isn't optional. Here's where we have it — and the workflows we've shipped, monitored, and kept running.
Healthcare & Life Sciences
HIPAA-compliant prediction, medical imaging, and clinical decision support that survives audit.
Financial Services & Fintech
Fraud detection, credit risk, document automation, and regulatory reporting that holds up under scrutiny.
Retail & E-Commerce
Demand forecasting, recommendation engines, visual search, and dynamic pricing tuned to real customer behaviour.
Logistics & Supply Chain
Route optimization, ETA prediction, warehouse vision, and capacity planning for fleets that can't pause.
Manufacturing
Predictive maintenance, defect detection, and yield optimization that pays back before the next quarter.
Energy & Utilities
Load forecasting, asset reliability, and anomaly detection on sensor data — across grids that never sleep.
Don't see your industry? The patterns transfer. The vocabulary is what we learn fast.
ML SOLUTIONSWhy Teams Pick TAK DEVs
We Tell You When Not To Build
Plenty of problems don’t need ML. We’ve talked clients out of six-figure builds when a rules engine and a clean dataset would do the same job. You’ll spot us by the absence of upsell.
We Ship In Weeks, Not Quarters
Average production deployment: 12 weeks from kickoff. We use bi-weekly sprints, working prototypes, and small senior teams that don’t need 14 meetings to make a decision.
We Own The Whole Lifecycle
Data engineering, model development, deployment, monitoring, retraining. One accountable partner, not five handoffs across vendors with different Slack workspaces.
We Build Skills, Not Dependency
Documentation, knowledge transfer, and clean code are part of the deliverable. If you want to bring everything in-house in 18 months, we’ll help you do it.
Results You Can Show
Your Board
Numbers from real engagements. Averaged across production deployments. Specific client logos and case studies available under NDA.
40%
Prediction Reliability
Improvement in reliability of business predictions and operational decisions.
50%
Goal Alignment
Better alignment between deployed models and actual business goals.
25%
Decision Time
Reduction in time spent on routine decision-making through automation.
30%
Complex Problems
Improvement in solving complex, previously "un-automatable" business challenges.
20–35%
Infra Cost
Reduction in cloud infrastructure cost for ML workloads after our optimization audit.
70%
Manual Review
Drop in manual review time on high-volume classification workflows.
Measured against client baselines over 6–18 month engagements. We'll show you the math.
ML SOLUTIONSTestimonials
I'm happy with TAK Devs Pvt Ltd's work quality. Our engagement with TAK Devs Pvt Ltd is a huge success. Our project is very complex and has many engineering metrics and variables, and the team delivers high-quality work.

TAK Devs Pvt Ltd delivered a robust system designed to handle 2 million daily users, achieving a seamless integration of PDF creation as part of the authentication process. The team consistently met deadlines and was highly responsive, flexible, transparent, understanding, and proactive.

Thanks to TAK Devs Pvt Ltd, the client can seamlessly track session duration, user engagement, and login metrics. They also can efficiently monitor appointment bookings, assess client-therapist match rates, and collect feedback. The service provider's knowledge and quality delivery are exemplary.

TAK Devs Pvt Ltd delivered a functional POC and offered detailed guidance throughout the development process. The team was helpful in explaining the project's complexities for the client to understand everything thoroughly. They communicated via virtual meetings, email, and messages.

Great communication, top understanding of Spec, autonomous development. Everything Perfect.

Real professionists, always ready to help our resident team. It's a pleasure to work with them.

Great work, implemented everything 100% as per our specifications, and very fast!

TAK Devs Pvt Ltd's efforts have been met with positive acclaim. The team is always available and communicative via virtual meetings and email. Their software development expertise and listening skills make them stand out.



Frequently Asked Questions
What are custom machine learning solutions, and why not just use ChatGPT or AWS SageMaker?
Custom machine learning solutions are ML models built specifically for your data, workflows, and business goals, instead of pre-trained, one-size-fits-many APIs.
When generic AI is enough:
- Common tasks (transcription, basic summarization, common-language translation).
- Low-volume use cases where API cost stays manageable.
- Problems where your context isn’t materially different from the public internet.
When custom ML wins:
- Your data is proprietary, domain-specific, or regulated.
- You need accuracy on your edge cases, not average-case demos.
- Latency, cost-per-prediction, or on-premise deployment matter.
- You want a defensible moat, not a model your competitor can rent for the same price.
How long does it take to build and deploy a custom ML model?
Most projects move from kickoff to production deployment in 8 to 16 weeks, with our average around 12 weeks. The biggest variable is data readiness, not model complexity.
Typical timeline:
- Weeks 1-2: Discovery, data audit, scoping.
- Weeks 3-8: Data preparation, model development, iteration.
- Weeks 9-10: Deployment, integration, load testing.
- Weeks 11-12: Monitoring setup, handoff, documentation.
Yes, you can do it faster. No, you probably shouldn’t.
How much does a custom machine learning solution actually cost?
It depends on data complexity, integration scope, and ongoing operations. We work in three engagement shapes:
- Discovery Sprint (4 weeks): Data audit, feasibility, and prototype. Fixed price.
- Full Build (8-16 weeks): Production-ready model, deployment, and handoff. Scoped fixed price after discovery.
- MLOps Retainer (ongoing): Monitoring, retraining, optimization. Monthly SLA.
We share indicative ranges on the discovery call. No surprise invoices, no “change request” gymnastics.
What if our data is messy, incomplete, or stuck across seventeen systems?
Welcome to ML in the real world. This is the situation in roughly 90% of engagements, and it’s exactly what data preparation and feature engineering exist to solve.
How we handle it:
- Data readiness assessment in the first two weeks, with an honest gap analysis.
- Pipelines that unify, clean, and validate data from your existing sources.
- Synthetic data techniques when real data is scarce or sensitive.
- Clear flags when a data problem must be fixed before modelling can usefully proceed.
Will the model still work six months after deployment, or will it quietly rot?
Untouched models drift. That’s not a bug, that’s reality. Our MLOps practice exists specifically so your model doesn’t quietly rot.
What ongoing operations actually mean:
- Continuous monitoring for accuracy decay, data drift, and concept drift.
- Automated retraining pipelines that update the model on new data.
- Alerts when performance crosses your tolerance threshold.
- Monthly model health reports tied to your business metrics.
Who owns the model and the IP we pay you to build?
You do. Full stop.
The model, training pipelines, code, documentation, and data transformations are all yours. We don’t retain ownership of client IP, and we don’t reuse client data in other engagements. It’s in the contract, and we’d be happy to walk you through it.
Do you work with regulated industries like healthcare or finance?
Yes. Compliance constraints are part of model design from day one, not an afterthought.
- Healthcare: HIPAA-aligned data handling, PHI safeguards, audit trails, explainability.
- Financial Services: Model risk management, explainability for regulators, bias auditing.
- EU operations: GDPR-aligned data practices and EU AI Act readiness for high-risk use cases.
We’ve delivered production ML inside regulated environments, including a recent HIPAA-compliant deployment shipped in 12 weeks.
Can you integrate with our existing stack (AWS, Azure, GCP, on-prem)?
Yes. We deploy where you already operate, not where we’d prefer to operate.
- AWS: SageMaker, Bedrock, Lambda, ECS, S3, Glue.
- Azure: Azure ML, AI Foundry, AKS, Synapse, Functions.
- GCP: Vertex AI, BigQuery ML, Cloud Run, Dataflow.
On-Premise & Hybrid: Kubernetes, MLflow, Kubeflow, air-gapped deployments where required.
What happens if we want to take everything in-house later?
Then we help you do it cleanly. Knowledge transfer, documentation, runbooks, and a structured handoff are built into every engagement.
We’d rather you keep working with us because we earn it, not because the codebase is unreadable without our help. That’s not how trust works.
How is this different from hiring an in-house ML team?
Hire in-house when:
- ML is core to your long-term product and you can attract senior talent.
- You have steady, multi-year ML roadmap with consistent demand.
- You’re prepared for 6-12 month hiring cycles and senior ML salaries.
Use TAK DEVs when:
- You need a working production model in months, not after hiring rounds.
- Your ML needs are project-shaped, not platform-shaped.
- You want senior expertise without the overhead of building a full ML org.
- You’d rather scale capability up and down based on actual demand.
What's the first step if we want to explore working together?
A 30-minute discovery call. Bring:
- A brief description of the problem you want ML to solve.
- Rough sense of your data (sources, volume, sensitivity).
- Your target timeline and any constraints (regulatory, budget, infrastructure).
We’ll come prepared with honest first thoughts, including whether we’re the right partner. If we’re not, we’ll usually know who is.